
[Solved]-Python Work Third Function Def Mandelbrotmodel Sentence Minfreqfortop 10 Given Sentence Wh Q37171709
python. just work on third function defMandelbrot_model(sentence, minFreqForTop = 10):
given sentence with white spaces split sentence by space then countfrequency of unique words and sort from smallest to largest.Thanks

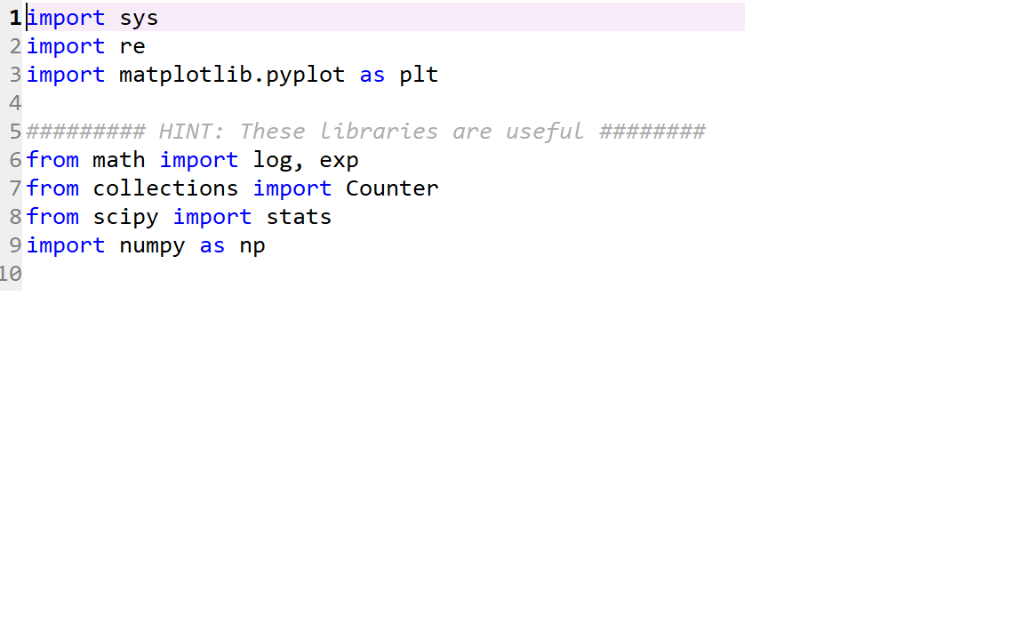
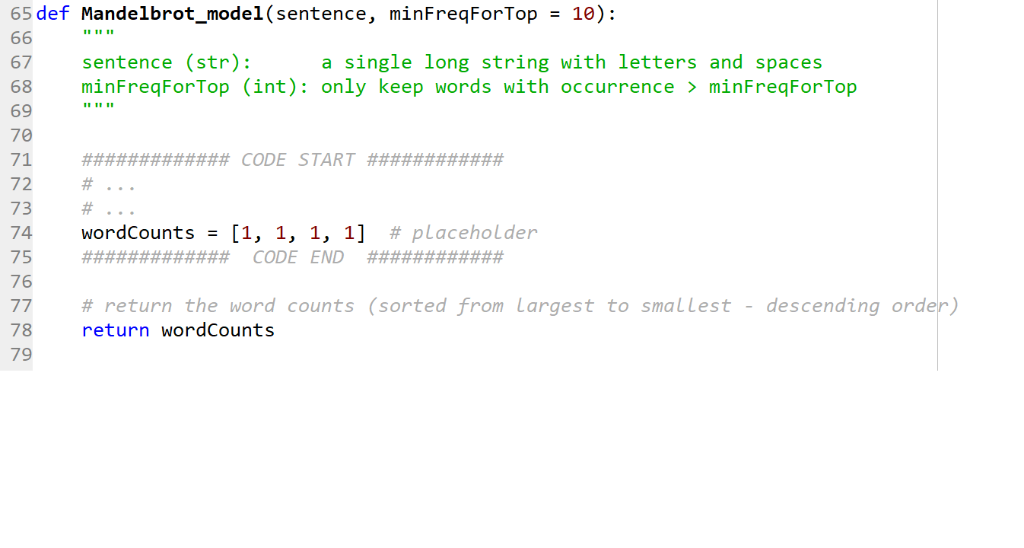 here’s the first line of theinput txt. file
here’s the first line of theinput txt. file
d dad abc a bb cbd babadcadddcacb daa b adcdbbaadbba cdadb d c dcbbc dd ad abcdcaba acbd cadc cad daac ba Fix an alphabet of some finite size, e.g., the binary alphabet 0,1), the nucleotide base alphabet {A, C,T, G), or the English alphabet of 26 letters {a,..,z). Your alphabet size should be a tunable parameter of your code. Note that it doesn’t matter what letters you use- in fact you can use numbers or symbols or anything else – all that matters is the alphabet size. . Add a space to your alphabet. Generate a long random string from this augmented alphabet, where each character in the string is selected uniformly at random from the set. Split this long random string into “words”, where each word is a maximal contiguous string of letters not incluing a space. Tally all the words found in the string, and sort the counts in decreasing order. Thus, the words are sorted in noincreasing order of frequency of occurrence, and the counts form a nonincreasing sequence. The claim is that the word frequencies generated by this simple model will follow Zipf’s law, even though there is no influence of “language” in the design of the random string Please implement the above process in Python code, and write a text file holding the frequencies of the most frequently found words in your random string. Now, use this file as the input to your solution for Problem 1. Your implementation should be in the form of a function that takes as input three parameters: the alphabet size, the string length, and a “minimum count” parameter. Just as the input used in Problem 1 was the top 5, 000 most frequently used words, the minimum count parameter will keep only those words whose frequency of occurrence was higher than that parameter. The reason for this is that the frequency plot will not appear as a straight line for all the words that have frequency of occurrence of one, and this will “throw off” the accuracy of the regression line. Try experimenting with different alphabet sizes such as 2, 4, 8, and see if you can understand how and why the alphabet size affects the resulting plot. !import sys 2 import re Bimport matplotlib.pyplot as plt 4 5######### HINT: These libraries are useful ######## 6 from math import log, exp 7 from collections import Counter 8 from scipy import stat:s import numpy as np 1e 65 def Mandelbrot_model (sentence, minFreqForTop 10): 67 sentence (str) 68 minFreqForTop (int): only keep words with occurrence > minFreqForTop 69 70 71 72 # 73 74 wordcounts = [1, 1, 1, 1] # placeholder 75 ### 76 77 # return the word counts (sorted from largest to smallest – descending order) 78 79 a single long string with letters and spaces return wordCounts Show transcribed image text Fix an alphabet of some finite size, e.g., the binary alphabet 0,1), the nucleotide base alphabet {A, C,T, G), or the English alphabet of 26 letters {a,..,z). Your alphabet size should be a tunable parameter of your code. Note that it doesn’t matter what letters you use- in fact you can use numbers or symbols or anything else – all that matters is the alphabet size. . Add a space to your alphabet. Generate a long random string from this augmented alphabet, where each character in the string is selected uniformly at random from the set. Split this long random string into “words”, where each word is a maximal contiguous string of letters not incluing a space. Tally all the words found in the string, and sort the counts in decreasing order. Thus, the words are sorted in noincreasing order of frequency of occurrence, and the counts form a nonincreasing sequence.
The claim is that the word frequencies generated by this simple model will follow Zipf’s law, even though there is no influence of “language” in the design of the random string Please implement the above process in Python code, and write a text file holding the frequencies of the most frequently found words in your random string. Now, use this file as the input to your solution for Problem 1. Your implementation should be in the form of a function that takes as input three parameters: the alphabet size, the string length, and a “minimum count” parameter. Just as the input used in Problem 1 was the top 5, 000 most frequently used words, the minimum count parameter will keep only those words whose frequency of occurrence was higher than that parameter. The reason for this is that the frequency plot will not appear as a straight line for all the words that have frequency of occurrence of one, and this will “throw off” the accuracy of the regression line. Try experimenting with different alphabet sizes such as 2, 4, 8, and see if you can understand how and why the alphabet size affects the resulting plot.
!import sys 2 import re Bimport matplotlib.pyplot as plt 4 5######### HINT: These libraries are useful ######## 6 from math import log, exp 7 from collections import Counter 8 from scipy import stat:s import numpy as np 1e
65 def Mandelbrot_model (sentence, minFreqForTop 10): 67 sentence (str) 68 minFreqForTop (int): only keep words with occurrence > minFreqForTop 69 70 71 72 # 73 74 wordcounts = [1, 1, 1, 1] # placeholder 75 ### 76 77 # return the word counts (sorted from largest to smallest – descending order) 78 79 a single long string with letters and spaces return wordCounts
Expert Answer
Answer to python. just work on third function def Mandelbrot_model(sentence, minFreqForTop = 10): given sentence with white spaces… . . .
OR
